![]()
OrbitLens Ace → ace.orbitlens.io
忙しい四半期は、いくらでも演出できる。二年後もそこに残っているコードは、そうはいかない。
人を測るのに使われてきた指標を思い浮かべてほしい。そのどれもたぶん、本当の仕事をしないまま数字だけ上げる方法を、誰かがもう見つけている。
行数は書いた量に報酬を出したので、みんな書いた。コミット数はコミットに報酬を出したので、コミットは細かく刻まれた。ベロシティは消化ポイントに報酬を出し、ポイントはじわじわ膨らんで「3」がほとんど何も意味しなくなった。DORA はデプロイ頻度を測り、些末な変更が勝手に流れ始める。code health 系が寄りかかる churn ですら、意図的に下げられる数字だ。下げられるということは、その下にある散らかりの代わりに、数字の方を管理できてしまうということでもある。
別に、誰も不正をしていない。グッドハートの法則が、いつも通りのことをしているだけだ。挙げた数字はどれも「活動量」を測っている。そして活動量は、安く作れる。活動量に報酬が付いた瞬間、もっと報酬を得る一番速い道は、活動量を増やすことになる。その活動量が本来は何の兆候だったのか、とは無関係に。
だから問う価値があるのは「どの活動量指標が一番マシか」ではない。git の履歴の中に、もっと忙しくするだけでは動かせないものが、そもそも何かあるのだろうか。
ひとつだけ、ある。賢かったからではない。それが何でできているか、というだけの話だ。
残るものは、活動ではない
ある人が書いた行を全部取って、しばらく待つ。それから「頑張ったか」より小さいことを訊く。その行は、まだそこにあるか。revert されず、書き直されず、誰かの refactor にそっと飲み込まれもせず、HEAD でまだ荷重を受けているか。
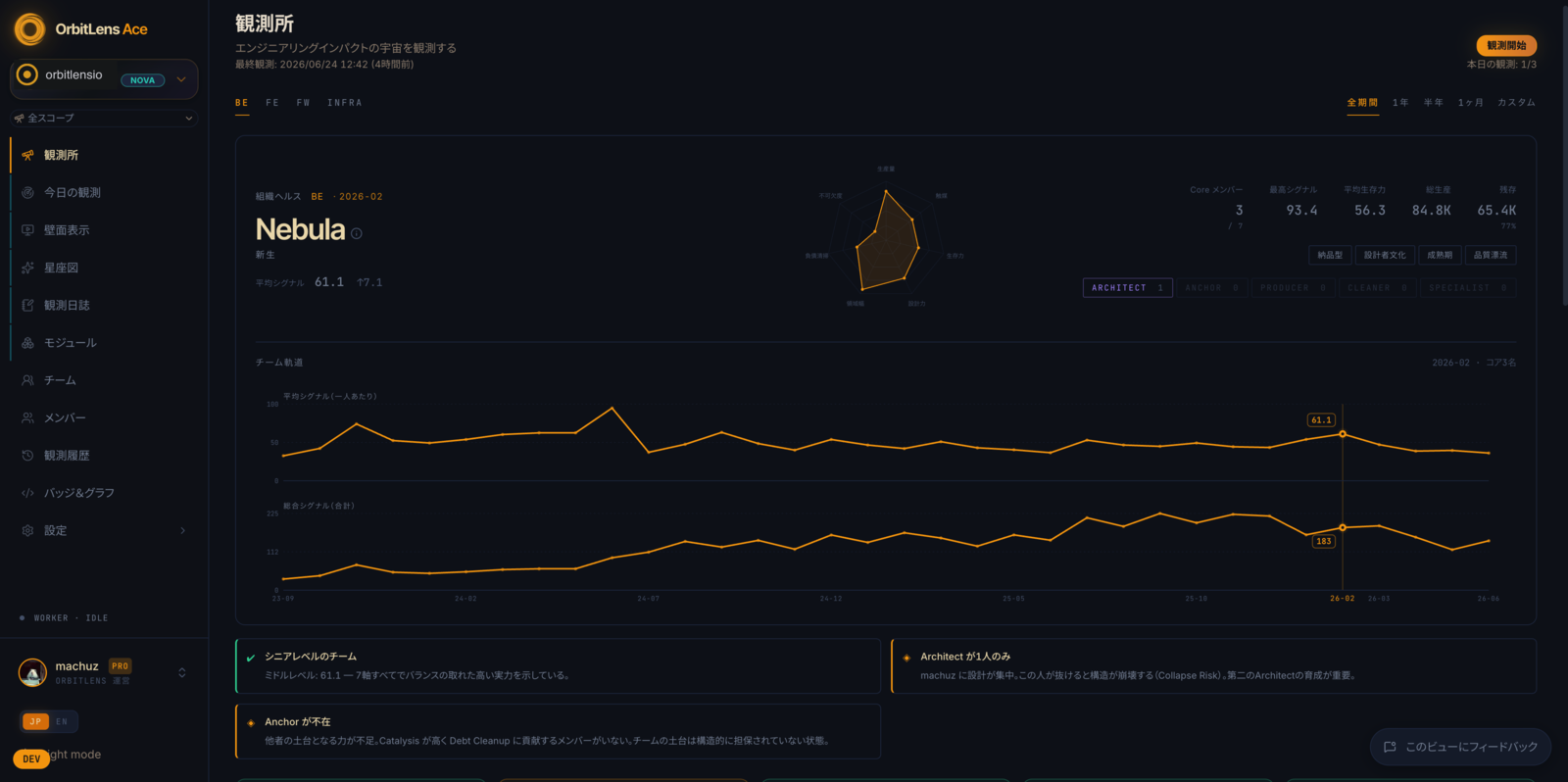
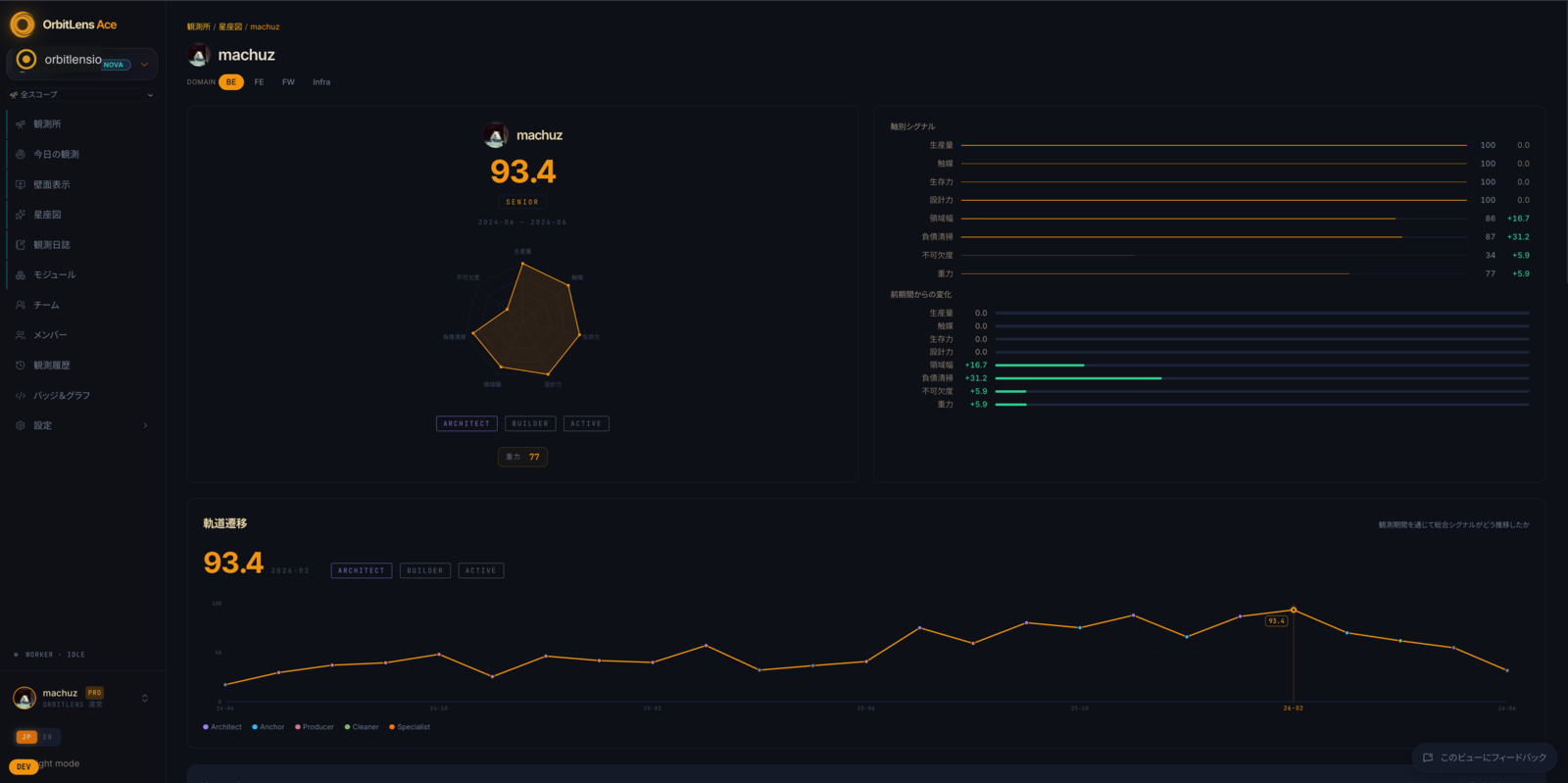
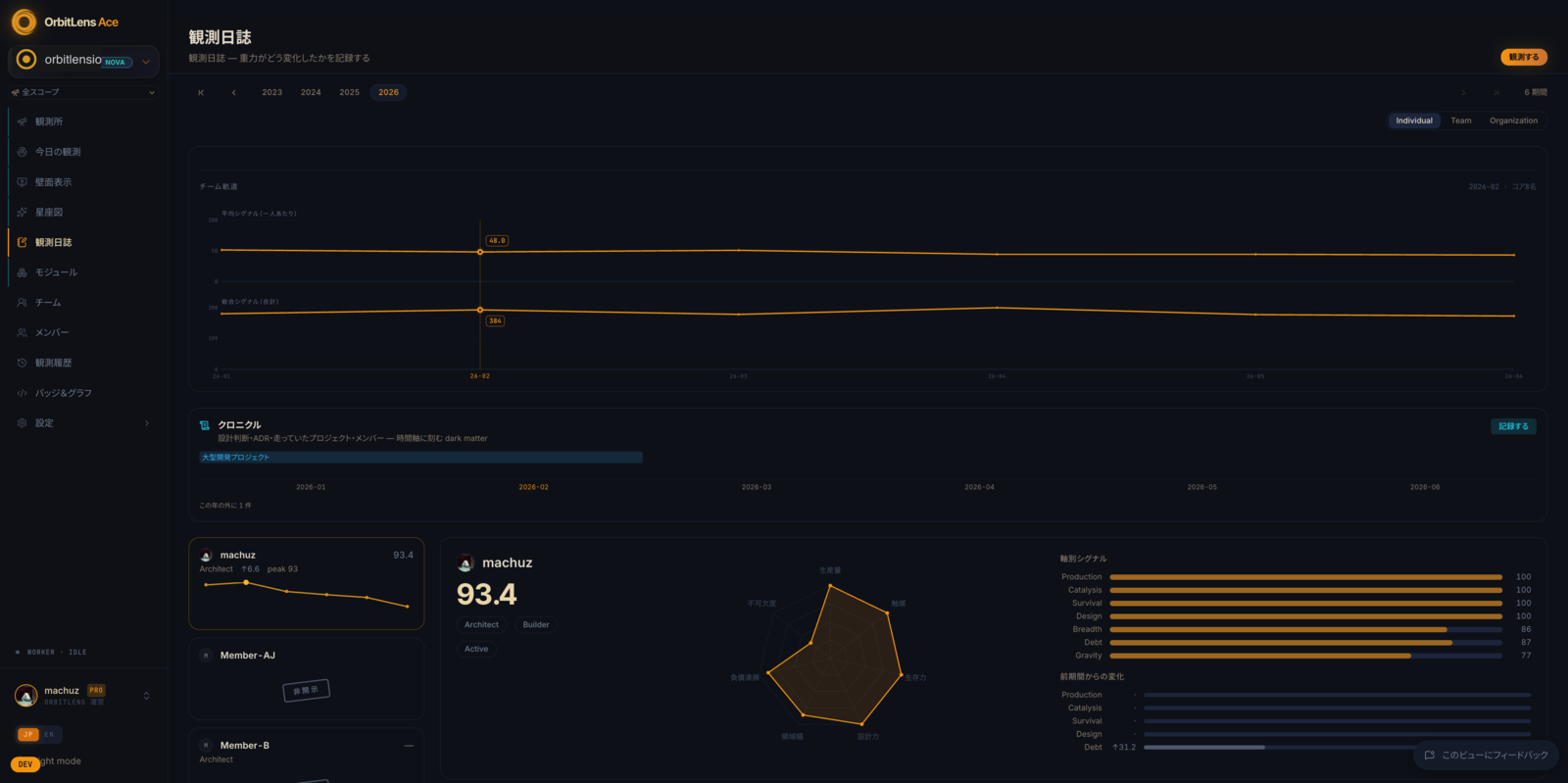
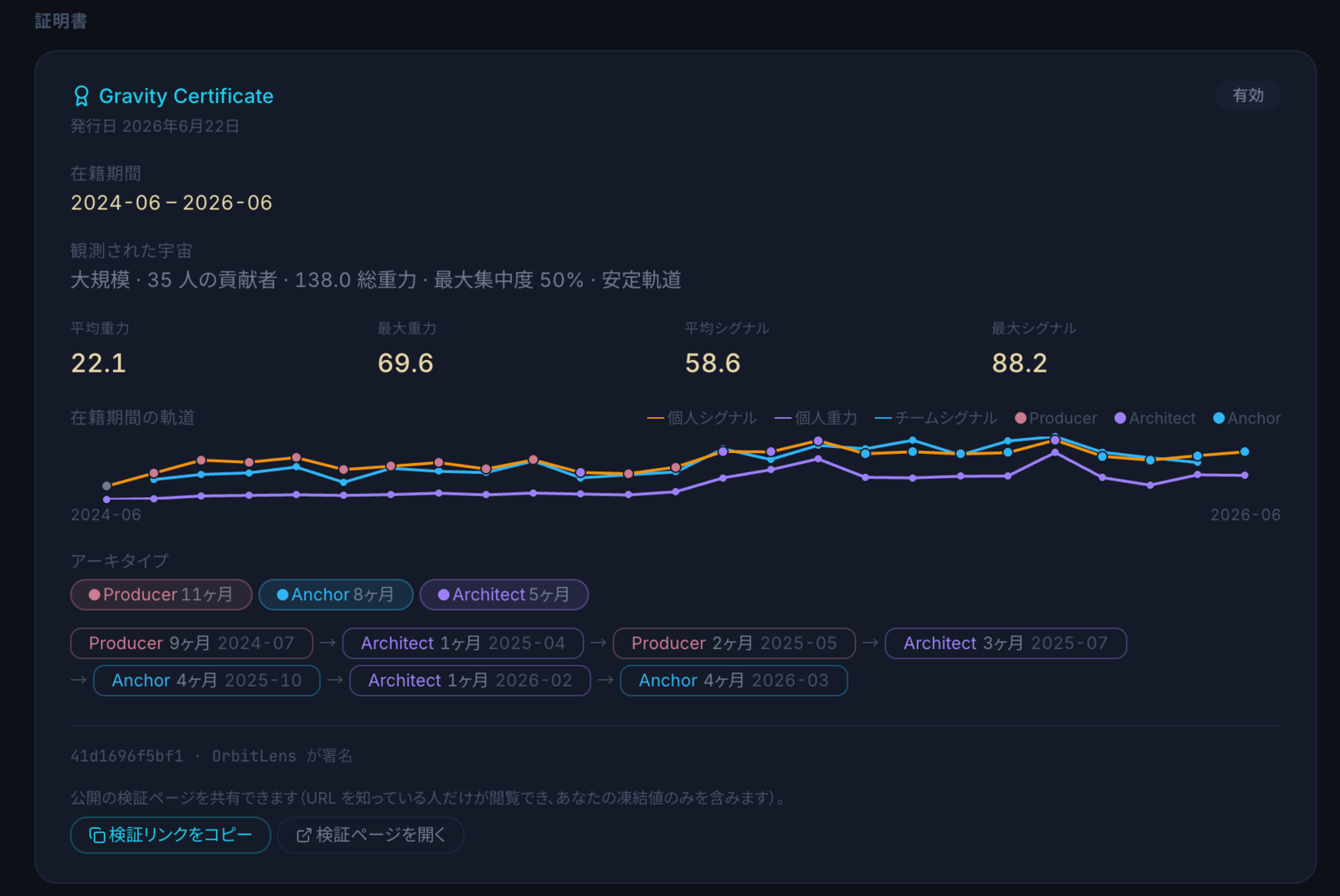
それが survival だ。時間減衰の git blame で読む。行の重みは月ごとに薄れていき、その行が存在し続けなければ消える。そして他の誰かがその上に積んだとき、重みは増す。他人が build-on した survival を、私たちは gravity と呼んでいる。書いた本人より長く残る、構造の引力だ。
ゲームしようとして、各手がどこへ流れるかを見てほしい。
コミットをひとつから百に割っても、survival が数えるのは残った行で、コミットではない。同じ十行を触る百コミットは、十行しか残さない。整形や busywork を書けば、それは自分でスコアから自分を消していく。書き直されるコードは、定義からして残らなかったコードだからだ。ファイルを激しく叩くほど、後に残って数えられる叩きは減る。膨大な量を書いても、残る分しか計上されない。半減期の短い量は、誰の量とも同じ速さでゼロへ落ちていく。
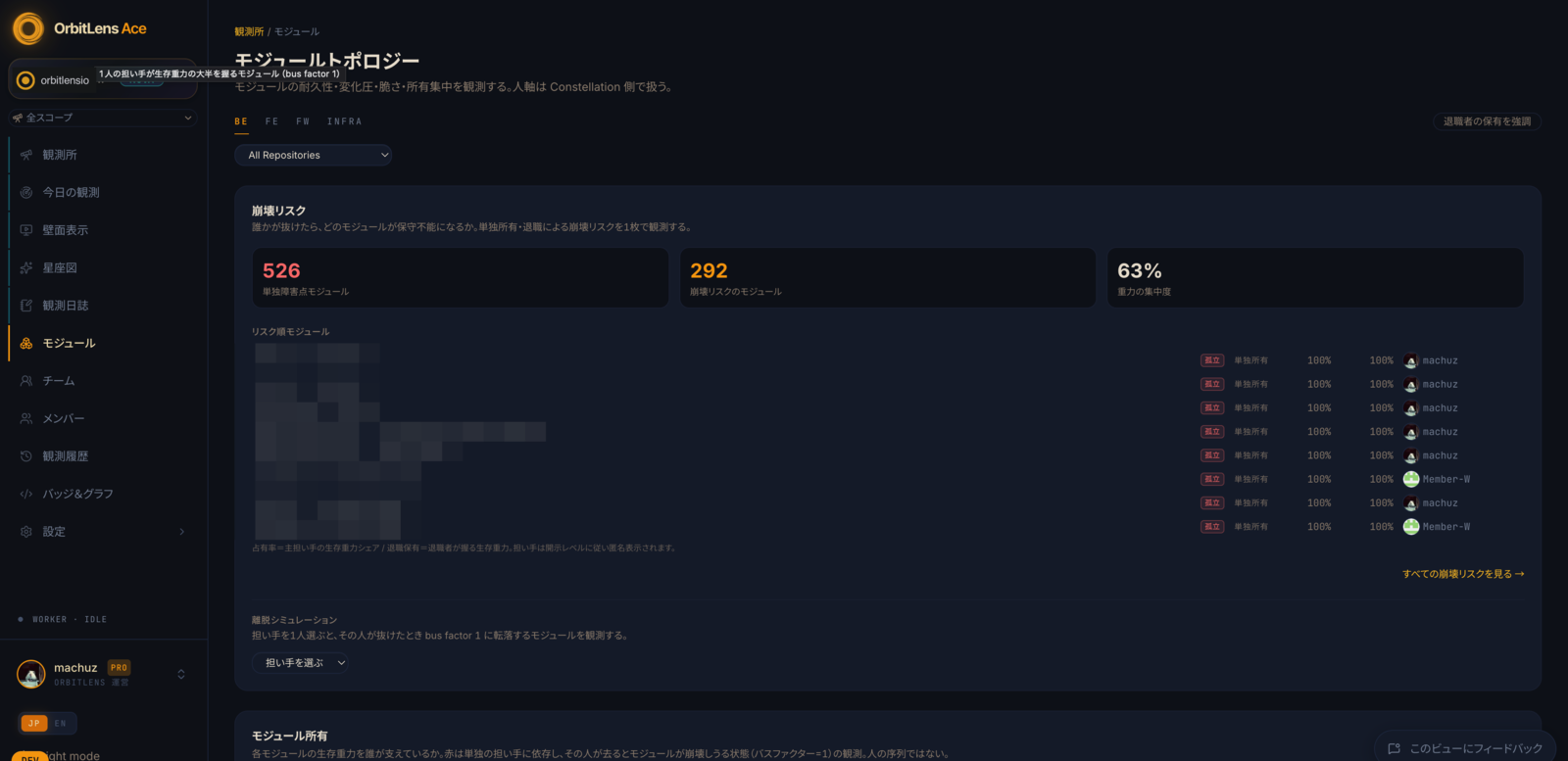
私的帝国を築く手は、gravity で割れる。誰も触らないコードは survival では残っても、gravity は「他人がその上に積んだか」を訊く。他人が何ヶ月もかけて、あなたの仕事を土台に選ぶか剥がすかで寄与する項で、これは自分では供給できない。
ただ、もう一段ねばる手が残っていて、それが継ぎ目を突く。survival の重みは exp(-経過日数/τ)——行が書かれてからの日数で決まる。書き直せば blame の author_date が更新され、経過日数はゼロに戻り、重みは満タンに戻る。だから自分のコードを定期的に触り直し、他人の refactor を territorially 押し返していれば、誰の build-on もないまま survival を高く保てる。皮肉は逆側にも効く。本当に堅牢で書き直す要らないコードほど、経過日数が伸びて減衰する。素の survival は、最も durable なコードを減点し、触り続けられたコードに得点を与えうる。(別の放棄分析でも同じ継ぎ目が出た——survival は補充が止まると落ちる。つまり一部は「保守の直近性」を測っていて、その保守は自分ひとりでも供給できる。)
だから、忙しさで動かせない核は、素の survival ではない。自己churn で満タンに戻せるなら、survival はまだ活動量を引き切れていない。引き切れないぶんを名指すのが gravity、others-contested の gate だ。触り続ける territorial 帝国は survival を保っても gravity はゼロで、τ が月単位である以上、この churn は永久に続けないと減衰する。そのあいだ gate は「他人が積んだか」を訊き続け、自己保守はその問いに答えられない。自分の手を通らない項は、他人があなたのコードに積んだかどうか、そこに絞られる。
量は、ほとんど予測しない
survival が出力に化粧をしただけなら、一番コミットする人が一番 survival を持つはずだ。そうはならない。
7つの OSS リポジトリ、547人の実貢献者で見ると、コミット数と、残ったコードの質量の順位相関は ρ = 0.28 だった。ログの中で忙しいことは、誰がまだコードベースに立っているかの、一桁%しか説明しない。7つのうち3つでは、最多コミッターと最多 survivor が、そもそも別人だ。
もっと鋭い形を、ある小さなプロダクションチームの中で見た。ある時点で、一人のエンジニアが同僚のおよそ十五倍の survival 質量を持っていた。活動量で読むなら、圧勝だ。二年経って、その差の大半は、まだ生きているコードベースの普通の churn に上書きされ、同僚の仕事の方が、いつのまにか皆がそれを土台に書き進める部分になっていた。順位を直す評価会があったわけではない。時間が、両者の上を同じように通り過ぎることで、直した。
(名前は本題ではないし、私たちは公開しない。同僚を公の場で順位づけてしまう数字こそ、この記事が反対している当のものだ。survival はコードの水準で読む。人の値打ちの水準では、読まない。)
なぜ、今なのか
ソフトウェアの歴史の大半で、活動量はまともな代役だった。残るコードが欲しければ、たくさん書くのは実際ひとつの手で、書くのが高くついたぶん、量が意図とそこそこ相関していた。
そこへモデルが1分に千行を吐き始めて、代役は崩れた。コミット数、diff の大きさ、PR のスループット。コードの半分が生成されるリポでは、それらはタダで膨らむ。希少でなくなったものを測る指標は、何も測っていない。
立っているのは survival の層だ。モデルはコードを生成できるが、それが残るかは後で決まる。変更に耐えるか、誰かが上に積むか。著者が人でも機械でも握れない、その二つで決まる。だからダッシュボードの残りがノイズで埋まっていくほど、残った層だけが、リポジトリでまだ信号を持つ最後の場所になる。
survival で「ない」もの
ここで、恐怖を売るこのカテゴリの他社から離れる。survival は美徳ではない。良いから残るコードもあれば、誰もが触るのを恐れる隅にあるから残るコードもある。持続と価値は別物で、「他人が積んだから残った」と「見捨てられたから残った」を分けるのは、本物の労力が要る。しかもその分離は、群衆がいないとそもそも働かない。三人のチームでは独立した手が足りず、gate は発火せず、指標は生の持続へ寄り戻る。そのことは、そのまま言う。
そして survival は予測しない。残ったものを告げるだけで、残るものは告げない。耐久性を予測できるかは本気で検証した。多くのリポで、綺麗には予測しなかった。その結果は、都合の悪かった部分も含めて、いずれ全部書く。勝ちしか報告しない観測所は、観測所ではないからだ。
主張はこれだけで、しかも小さい。誰を昇進させるべきか、次にどのファイルが壊れるかを告げる数字ではない。git が記録する全ての中で、忙しさひとつでは動かせないのは、他人があなたのコードに積んだかどうか——survival を others-contested で gate した gravity——で、それは自分の手の外にある。忙しさがタダになった年に、それが結局、読む価値の残った測定だった。
望遠鏡は曲げない。地面にあるもの、残ったコードと、それがまだ持つ引力を読み、その読みを人の上のスコアボードに変えることはしない。それを自分のリポジトリに向けたい観測器だと思うなら、git だけで、ローカルで動き、外へは何も送らない。